< Aritalab:Lecture | Biochem(Difference between revisions)
|
|
| Line 16: |
Line 16: |
| | |} | | |} |
| | | | |
| − | ===タンパク質の構造===
| |
| − | タンパク質は20種類のアミノ酸から構成され、アミノ酸どうしはアミノ基とカルボキシル基の間にペプチド結合を形成します。
| |
| − | この結合は共鳴によって二重結合性を帯びるので平面構造をとります。
| |
| − | Cα(アミノ酸の中心炭素)の間に炭素と窒素が1個ずつ入りますが、平面が固定されるのでC<sub>α</sub>-N結合角(φ ファイ)とC<sub>α</sub>-C結合角は(ψ プサイ)の二結合ぶんで立体配置を決定できます。
| |
| − |
| |
| − | ====一次構造====
| |
| − | ペプチド結合によって連結されたアミノ酸の配列を一次構造といいます。コドンの並び順で最初にくるアミノ酸側がアミノ基末端 (N末端)、最後のアミノ酸側がカルボキシル末端 (C末端) となります。
| |
| − |
| |
| − | 代表的な一次構造のデータベースには以下のものがあります。いずれも特徴的なアミノ酸配列という形式で機能や構造を表現しています。
| |
| − |
| |
| − | * [http://prosite.expasy.org/ Prosite] ... タンパク質のドメインや機能モチーフ
| |
| − | * [http://smart.embl-heidelberg.de/ Smart] ... ドメインやタンパク質相互作用の計算機による予測サーバー
| |
| − | * [http://www.ncbi.nlm.nih.gov/cdd/ CDD] ... 機能、構造ドメインのメタデータベース
| |
| − |
| |
| − | ====二次構造====
| |
| − | タンパク質のドメインは、二次構造という単位で理解されます。二次構造は水素結合や分子間力で構成されるため、加熱や pH、尿素などの変性剤、界面活性剤などで変化します。
| |
| − |
| |
| − | 水素結合のエネルギーは、1結合あたり 2 ∼ 10 kcal/mol と見積もられており、共有結合と比較すると 1/10 以下になります。
| |
| − |
| |
| − |
| |
| − | 二次構造の予測にはニューラルネットワークや隠れマルコフモデルが使われますが、最近は psi-BLAST など配列アライメントに基づくツールもよく使われます。
| |
| − | 予測ツールでは[http://www.ebi.ac.uk/Tools/pfa/iprscan/ InterProScan] がよく知られています。これは既存のツール 10 種以上による予測結果をまとめてE-mailで返してくれるシステムで、メタツールと呼ばれます。おおよそ 80 % 程度の精度で二次構造が予測できると考えられています。
| |
| − |
| |
| − | * α-へリックス
| |
| − | アミノ酸が平均3.6残基で右巻きにらせんを巻いた構造です。(左巻きもありますが、数は少なくなります。)
| |
| − | ''n'' 番目のアミノ酸におけるペプチド結合の -C(=O)- 部分が、''n'' + 4 番目のアミノ酸におけるペプチド結合の -N(H)- と水素結合して形成されます。この一般系を 4-α へリックスと呼びます。
| |
| − | このほか 3 アミノ酸、5 アミノ酸で一周する構造もあり、それぞれ 3<sub>10</sub> へリックス、π へリックスと呼ばれます。
| |
| − |
| |
| − | * β-シート
| |
| − | 伸長したアミノ酸が並行に並んだストランド構造です。
| |
| − | シートの間で-C(=O)- 部分が -N(H)- と水素結合して形成されます。
| |
| − | ストランドが同じ向きに並んだ場合を並行 β シート、互い違いに並んだ場合を逆並行 β シートといいます。
| |
| − |
| |
| − | *ループ領域、ターン領域
| |
| − | α-へリックスやβ-シートは、特定の構造をとるループや、構造が不定のディスオーダー領域で連結されます。細胞外にある多くのタンパク質では、硫黄を含むシステインどうし間にS-S架橋をつくったジスルフィド結合が立体構造を安定化させます<ref>細胞内のタンパク質はS-S架橋をほとんど作りません。</ref>。
| |
| − |
| |
| − | {| class="wikitable"
| |
| − | ! α-へリックス
| |
| − | ! β-シート
| |
| − | ! ループ、ターン
| |
| − | |-
| |
| − | | [[Image:Lecture-Biochem-Protein-alpha.jpg|100px]]
| |
| − | | [[Image:Lecture-Biochem-Protein-beta.jpg|100px]]
| |
| − | | [[Image:Lecture-Biochem-Protein-turn.jpg|100px]]
| |
| − | |-
| |
| − | | グリシンやプロリンは通常含まれない(らせんを妨げる)。電荷を持つアミノ酸や大きなアミノ酸も比較的少ない。
| |
| − | | イソロイシンやバリンのような疎水性残基が使われる。親水性の側と疎水性の側ができやすい。
| |
| − | | 急な角度を形成するためにグリシンやプロリンが多い。
| |
| − | |}
| |
| − |
| |
| − | ====三次構造====
| |
| − | いわゆるタンパク質の立体構造を三次構造といい、原子の座標であらわします。三次構造の形成にはアミノ酸側鎖どうしの疎水結合力が大きな役割を果たし、疎水性アミノ酸がタンパク質のコアを形成します。
| |
| − |
| |
| − | [http://www.pdbj.org/ Protein Data Bank] (PDB) は代表的な立体構造のデータベースで、およそ 10 万のタンパク質構造が登録されています。
| |
| − | 正確な立体構造はX線結晶解析やNMRで決定するしかありませんが、進化の観点から、構造既知の配列に似ている配列は、立体構造も似ていると仮定できます。
| |
| − |
| |
| − | {| class="wikitable"
| |
| − | |-
| |
| − | ! アミノ酸の保存率 || 検出できる代表的ソフトウェア || 進化的な考察
| |
| − | |-
| |
| − | | 30% 以上 || 殆どの配列解析ソフト || 同一祖先由来のホモロジーを持つ
| |
| − | |-
| |
| − | | 25%近辺 || Blast (E-value 10<sup>-4</sup>) || トワイライトゾーン。配列解析ソフトの限界
| |
| − | |-
| |
| − | | 20%以下 || PSI-Blast (E-value 10<sup>-4</sup>) || 立体構造比較が必須。
| |
| − | |}
| |
| − |
| |
| − |
| |
| − | ====四次構造====
| |
| − |
| |
| − | 複数のタンパク質サブユニットの空間配置を四次構造といいます。
| |
| − |
| |
| − | ===二面角===
| |
| − | アミノ酸の中心に位置する炭素 (C<sub>α</sub>) に注目すると、側鎖の他にそれぞれがペプチド結合に関わる -C(=O)- と -N(H)- が接続しています。
| |
| − | ペプチド結合は平面構造をとりますが、それぞれが -C-C<sub>α</sub> 軸と C<sub>α</sub>-N- 軸を中心に回転できます。
| |
| − | その回転角度 φ, ψ は ±180 ° の間をとることができ、二面角と呼ばれます<ref>
| |
| − | タンパク質の構造を表現する二面角に対するギリシャ文字は常に
| |
| − | : アミノ基側の結合がファイ φ ... C(i-1)−N(i)−C<sub>α</sub>(i)−C(i)
| |
| − | : カルボキシル基側の結合がプサイ ψ ... N(i)−C<sub>α</sub>(i)−C(i)−N(i+1)
| |
| − | を用います。
| |
| − | </ref>。
| |
| | | | |
| | ====ラマチャンドランプロット==== | | ====ラマチャンドランプロット==== |
Revision as of 11:03, 24 April 2012
タンパク質は20種類のアミノ酸が連なったポリペプチドです。
タンパク質を大きく分けると表のようになります。
| 水溶性タンパク |
球状 (globular) |
酵素や転写因子など。分子内部は疎水性、外部は親水性。
|
| 不定形 (disordered) |
真核生物に多い不定構造。親水性アミノ酸が多い。とりわけEPQSRKを含む。
|
| 膜タンパク |
受容体、トランスポーターなど。疎水性アミノ酸が多い。とりわけ膜貫通領域は疎水性。結晶化しにくい。
|
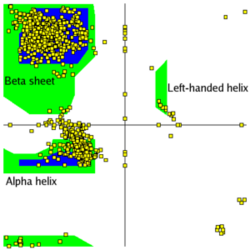
ラマチャンドランプロット
|
アミノ酸配列は、ペプチド結合における二面角のリスト φ1, ψ1, φ2, ψ2, ..., φN, ψN で表すことができます。
この値を平面に散布図としてプロットしたものをラマチャンドラン (Ramachandran) プロットと呼びます。
ラマチャンドラン (Gopalasamudram Narayana Ramachandran) は、インド出身の生物物理学者です。
ペプチド鎖の特徴をみるのに、各アミノ酸のφ角度とψ角度を平面にプロットする方法を考え出しました。
こうするとへリックスとシート構造がきれいに分離され、タンパク質の構造分類に使えます。
|
|
コンタクトマップ
縦(上から下にN→C)横(左から右にN→C)にペプチド鎖を並べ、Cα原子間の距離が10オングストローム以内であれば色を塗ったものをコンタクトマップと呼びます。
対角線は同一の残基がくるので黒くなります。α-へリックスはこの対角線上に重なる形で表示されます。
平行β-シートは対角線から離れた位置に同じ角度で現れ、逆平行β-シートは、対角線と直行する角度で現れます。
構造の分類と測定
タンパク質立体構造の研究はミオグロビン(myoglobin: 筋肉にある赤いタンパク質)から始まりました。ジョン・ケンドリュー(John Kendrew)がX線回折で世界ではじめてタンパク質の構造を明らかにしたのは1960年です(そんなに昔ではないのです)。立体構造解析に対する功績により、ケンドリューはわずか2年後の1962年にノーベル化学賞を授与されています(ペルーツと共同)。
DNAに比較すると、タンパク質の構造は遥かに複雑で理解が難しいものでした。
ドメインによる分類
タンパク質の構造は、長さが 50-150アミノ酸程度のドメインと呼ばれるブロックに分けて考えます。各ドメインは機能部位や疎水性コアを持ち、ドメイン間の二次構造どうしは近接しません。ドメインとはつまり、タンパク質の構造(および機能)モジュールと捉えられます。金属イオンと結合して構造を形成するドメイン(例. ジンクフィンガー)もあります。
立体構造を分類するデータベースには、手作業で構造を分けた SCOP (structural classification of proteins) や CATH があります。いずれもドメインを考慮した分類を採用しており、大きく分けると以下のようになります。(図はCATH DBより)
mainly α
|
mainly β

|
α and β
|
few structures

|
測定方法
- ゲル電気泳動
タンパク質は帯電しているので、ポリアクリルアミド電気泳動 (PAGE) で分離できます。
- X線回折
タンパク質を結晶化させられる場合はX線結晶解析により原子位置を特定できます。
粒子加速器から得られるX線を用いると、Cαほか、重い原子の位置を計算できます。水素の位置はわかりません。
- NMR解析
NMRとはNuclear Magnetic Resonanceの略で、原子核の磁気共鳴を用いて原子の位置を特定します。
- 解説、参考






